Case study
A multi-tenant AI SaaS on AWS, built and run solo for three years
Content Raptor is a B2B SEO and content intelligence platform I founded in 2023 and built alone: the architecture, the infrastructure, the AI pipelines, the on-call. It served 300+ paying customers and ingested 3M+ Google Search Console rows a day. This page is about the backend that carried it.
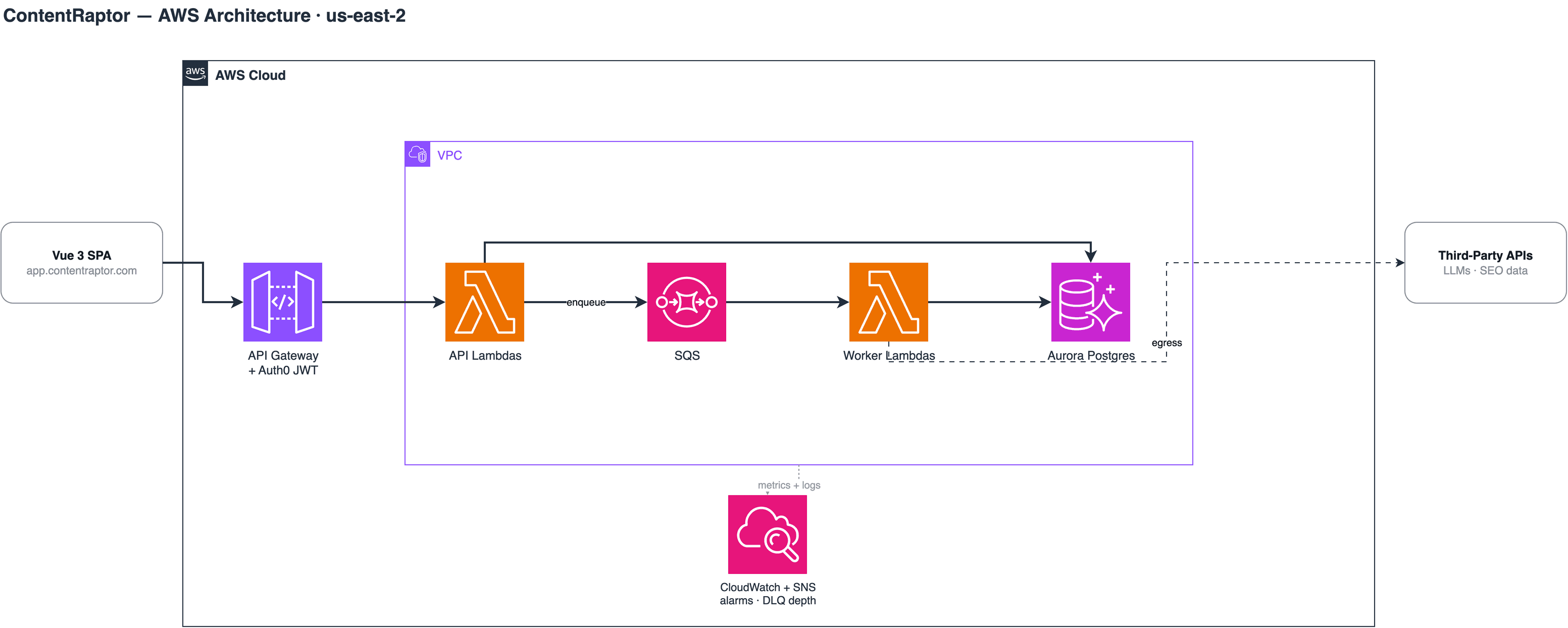
The shape of the system
14 Lambda functions split across an HTTP API tier (Auth0 JWT) and 10 SQS-driven async workers, plus a separate Python service for the NLP work: spaCy entity extraction and LDA topic modeling. Behind them, Multi-AZ Aurora PostgreSQL with hash-partitioned tables. Everything is codified with the Serverless Framework in stage-scoped dev and prod environments; nothing was ever click-built in the console.
The queue tier is the heart of it: ingestion fans out through SQS so a burst of customer imports becomes backpressure instead of an outage.
Decisions that mattered
Reserved concurrency per worker, sized by job profile
15 for Playwright SERP screenshots, 5 for AI generation, 1 for singleton imports. Caps blast radius and prevents a runaway workload from starving the rest.
Provisioned concurrency on the prod API Lambda
Two warm instances eliminate cold starts on the hot request path without paying for always-on containers.
Hash partitioning at 40 to 100 partitions per large table
Distributes I/O on the biggest tables and enables parallel scans for aggregates. This was half of the 16x ingestion speedup.
ReportBatchItemFailures plus custom error classification on SQS triggers
One bad message does not reprocess an entire batch. Permanent-vs-transient logic drops malformed messages to Sentry and retries network and throttling errors cleanly.
DLQ and CloudWatch alarm pattern on AI workers
Depth alarms route through SNS to ops email. Poison-pill quarantine, not silent failure.
Single NAT for a fixed egress IP
Required by third-party API whitelisting (DataForSEO, Google Search Console). A deliberate cost-vs-availability tradeoff for a single-region product.
What it produced
- Production traffic with no queue-backlog incidents under load.
- Re-architected ingestion to run 16x faster and cut the AWS bill in half doing it.
- Cut CI billed minutes by about 60% via job consolidation and path-based filtering.
- Clean cross-tenant isolation: zero leakage incidents across the life of the product.
Stack
AWS (Lambda, SQS, RDS Aurora, API Gateway, S3, VPC, IAM, Secrets Manager, CloudWatch, SNS), Serverless Framework, TypeScript and Node, Python, PostgreSQL, Auth0, Sentry, GitHub Actions.
Need a backend like this built or reviewed?
I consult on AWS architecture and run fixed-price AWS cost audits. More of my work is public at github.com/zkann.
📅 Book a free 30-minute call